| 数据问答最佳实践 | 您所在的位置:网站首页 › 智能问答服务机器人 大数据技术 › 数据问答最佳实践 |
数据问答最佳实践
|
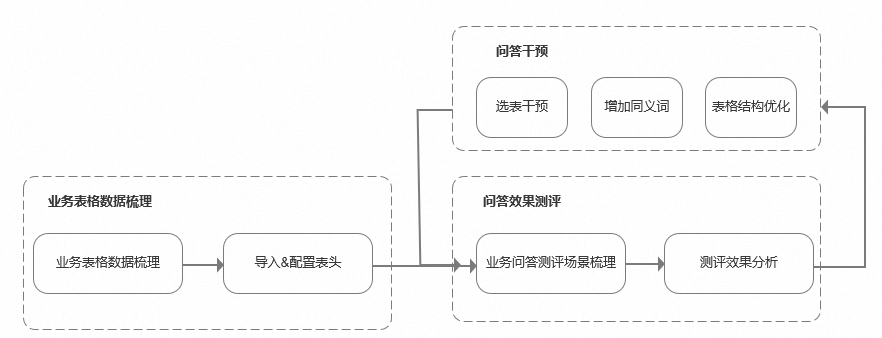
一、数据问答功能使用流程 数据问答整体使用流程上看,有三个步骤:业务表格数据梳理、问答效果测评和问答干预。 业务表格数据梳理:主要是在一定程度上规范实际业务表格数据,提高模型识别效果,主要包含业务表格数据梳理、导入和配置表头。 问答效果测评:主要是测试并干预实际数据问答效果,主要包括业务问答测评场景梳理、测评效果分析。 问答干预:主要是针对问答效果不好的点进行干预优化,主要手段包括表结构优化、增加同义词、选表干预。
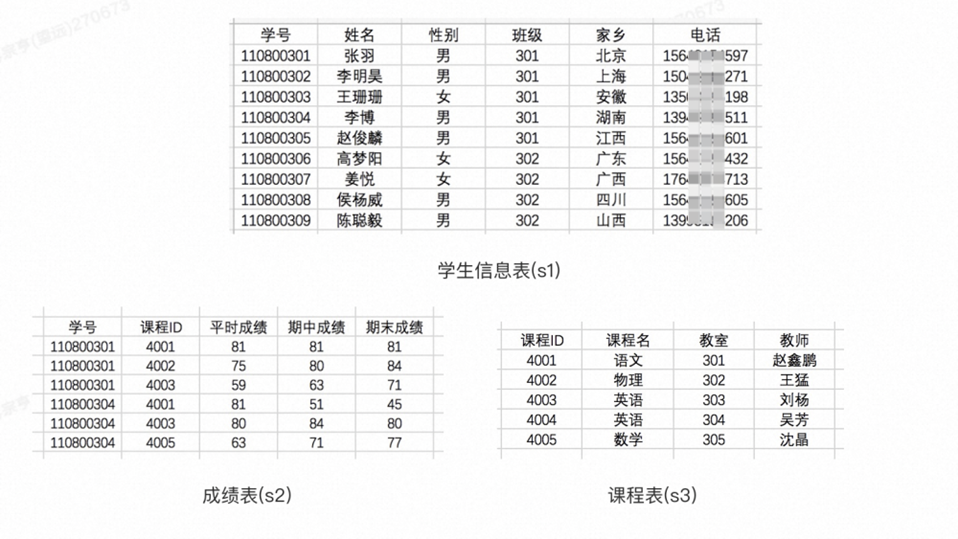
数据表中表头的名称与数据类型的定义能够影响大模型对用户问句的语义理解,因此有关数据定义的准确性及完整性十分重要。下文介绍表结构、表头、表值的规范并提供具体示例以供参考。 1.表结构规范:若用于数据问答的表格来源于数据库而非本地上传,尽量保证数据库中有关表格与其他业务隔离:如数据库中的某表格既用于A业务,又用于数据问答业务,则若由于A业务中需要,删除该表格中某些数据时,则可能会对数据问答业务产生不利影响。 适当设计宽表:宽表可以减少跨表查询,但需避免过度冗余,需要考虑到数据的更新。 说明使用宽表可以减少跨表查询:如A表格主要记录学生学习成绩信息,B表格主要记录学生兴趣爱好信息,通过将A表和B表结合为宽表C,通过C表既可以查询学生信息,也可以查询学生兴趣爱好。 宽表并非“越宽越好”,当表格中的列过多,对应表格更新和维护难度增大,成本变高。 当前数据问答支持表格最多100列。 多表关联时,区分主表和非主表:主表的数据通常为事实性数据,且不常修改(静态表);与主表相关的其他易变属性可以在另一张表(动态表)中维护,即为一对多的表依赖关系(动静分离);应避免多对多的表依赖关系。 说明多表关联可支持一个问题通过多个表格来查询,通过表头的关联关系实现跨表格的查询。且表格间除关联和被关联的表头,其他表头名不允许相同。被关联的表即为主表。 最多只支持3张表相互关联,且A表的一列不能关联B表的同时又被C表关联,可以A表的一列被B表和C表同时关联。 规避业务数据冗余:每行数据不应该有业务相关的冗余,给模型理解带来困扰,比如一张表中的数据如下: 大学 专业 研究方向 招生人数 北京工业大学 数学 应用数学 12 北京工业大学 数学 基础数据 12 北京工业大学 物理 应用物理 11 说明实际场景中,该表格表示:北京工业大学数学专业共招生12人,该12人可选择应用数学或基础数据研究方向。而不是数学专业的应用数学或基础数据研究方向各招12人。 当用户问“北京工业大学招生人数”时: 机器人回复答案:35人(数学专业的应用数学研究方向12人+数学专业的基础数据研究方向12人+数学专业的应用物理研究方向11人=35人)。 实际招生人数:23人(数学专业12人+物理专业11人=23人)。 解决方案:将“研究方向”和“招生人数”拆在两张表中,具体如下表所示: 大学 专业 招生人数 北京工业大学 数学 12 北京工业大学 物理 11 大学 专业 研究方向 北京工业大学 数学 应用数学 北京工业大学 数学 基础数据 北京工业大学 物理 应用物理 2.表头规范:表头名称:中文,为名词或短语(少于10个字),如材质、产品类型;同表/多表中的两个表头间避免存在语义交叉,如:“产品类型”与“分类”,两个表头从业务上有层级关系,若用户表述 “xxx类别”时,将无法准确召回对应表头值。 表头类型:根据存储的数据本身特点选择,支持文本型、数值型、布尔型、日期型、数组型等。 表头描述:可选,通常对表头名称进行解释,以便于人们理解该表头含义,如: 文本枚举类型:true代表含有灯泡;false代表不含有灯泡; 文本枚举类型:0代表已揽件;1代表已发货;2代表送货中;3代表已收货。 单位:可选,对数值类型的表头按需选择配置即可。 3.表值规范:表值应该与定义的表头类型严格匹配,如: 若表值只可能为数字或空,则表头类型应该为数值型。 若每个表值包含一个或多个枚举值,应选择数组型。 表值格式应该规整,如: 若表头名为“颜色”,则其候选值应该均为颜色,而不应该还包含颜色的描述(如:类似天空的浅蓝色)。 若表头名为“城市”,则其候选值应该为“北京市”、“上海市”,而不应该是“(11)北京市”。 表值的长度规范,如 若该表头需要参与筛选条件,则长度应该尽量短(少于10个字),以保证较好的召回效果。 若该表头仅用于查询返回(即不参与筛选条件),长度可放宽至 10000 字。 如果表值需要参与数值计算,需要定义为数值型,里面不能再加入其他文本,如 若表头名为“招生人数(不含推免)”,里面的表值需要参与数值计算,则需要把里面的列进行拆分,即应该从“【(600)工程师学院】【(02)02金融工程管理】研究方向:25(不含推免)”变成“25”。 4.规范表格示例示例一原表格: 表头名称 表头同义词 表头类型 表值示例(以|分隔) 产品类型 - 文本型 床垫(唯一值) 分类 种类 文本型 袋装弹簧|弹簧|泡沫等 材质 材料,用料 文本型 袋装弹簧|天然材料|弹簧|泡沫等 存在的问题: “产品类型”与“分类”两列语义上极易被误解。 “分类”与“材质”两列在表值上存在大范围重叠,统一更合适。 优化后的表格: 表头名称 表头同义词 表头类型 表头描述 产品类型 - 文本型 产品所属分类,如:床垫 材质 材料 文本型 产品核心材质,如:袋装弹簧|天然材料|弹簧|泡沫等 示例二原表格 表头名称 表头同义词 表头类型 表值示例(以|分隔) 座位数 乘坐人数,几人座,坐席数,容纳人数,座位,座位容量,座位数目,座位数量,座位设置,座椅数量 文本型 2人座|3人座 沙发内件包含物品 - 文本型 座垫、靠背垫、靠背和座框架、扶手、安装件 存在的问题: 座位数:非数值型,在问答时无法支持数值大小比较。 沙发内件包含物品:包含多值但未结构化,模型可能无法识别,需要将有关文本转成数组形式。 优化后的表格 表头名称 表头同义词 表头类型 表头描述 座位数(单位:人座) 乘坐人数,几人座,坐席数,容纳人数,座位,座位容量,座位数目,座位数量,座位设置,座椅数量 数值型 沙发内件包含物品 - 文本数组型 沙发内件包含物品清单,如:["座垫","靠背垫","靠背和座框架","扶手","安装件"] 示例三原表格 表头名称 表头同义词 表头类型 表值示例(以|分隔) 产品类型 - 文本型 产品所属分类,如:灯具 分类 - 文本型 装饰性灯具|LED灯条|LED夜灯|顶灯|台灯等 灯光颜色 - 文本型 暖白光|建议您使用LED灯泡 GU10。该款灯光是暖白光 连接电源种类 电源 文本型 该产品电池供电,须使用3节LR03 AAA 1.5V 电池,电池须另购|USB电源接口|嵌入式电线安装 存在的问题: “产品类型”与“分类”两列存在从属关系,如:“产品类型”为一级类别,而“分类”为二级类别,模型无法判定选择“产品类型”列,还是“分类”列。 “灯光颜色”列数据不规整,既存在标准的颜色,又存在描述性说明,问答链路无法支持作为条件筛选,应进行规整。 “连接电源种类”列为纯描述列,问答时无法支持作为条件筛选,应进行规整。 优化后的表格: 表头名称 表头同义词 表头类型 表头描述 产品类型 - 文本型 灯具 灯光颜色 - 文本型 示例值:暖白光|乳白色|日出黄 连接电源种类 电源 文本型 示例值:电池|USB|嵌入式电线 三、问答效果测评问答能力边界先了解一下当前问答能力支持的边界,以更有针对性地进行业务测评数据梳理。 支持的表结构:扁平结构:每一行记录代表一条完整的数据记录,列代表该记录中的一个属性。 关系结构:将数据分成多个表,每个表代表一个实体或关系,表之间通过主键和外键建立关联,具体如下图所示: 说明当前数据问答支持最多3张表关联查询。
单列查询:针对单列的数据进行查询,查询精度较高,如:北京大学归哪个部门管理; 多列查询:针对多列的数据进行查询,如:XXXX床垫的材质和硬度如何; 多条件并存:在查询/分析语句中,筛选条件存在多项,如:推荐一款黑色的不可调节的座椅。 此外,还具备一定的分析能力,如: 常见的聚合问法:计数、求和、最大、最小、平均; 常见的分析类问法:同期、同比、环比、占比、排名、排序等; 智子分析能力:因子分析、异常点检测、topN分析。 具体能力如下表所述: 能力项 用户问法示例 Select 各类聚合函数 最大值/最小值/平均值/总和 公司A2022年1月发电量最大值/最小值/平均值/总和是多少? 计数 每个地区有几个公司? 比较 北京各公司平均发电量和上海各公司2022年1月平均发电量对比? 环比 公司B2021年3月的发电量月环比? 2021年3月公司B平均发电量的日环比? 2021年第一季度公司B平均发电量的季度环比? 同比 2021年3月公司B发电量同比? 2021年3月公司B平均发电量同比增长多少? 趋势 2021年公司B每个月发电量趋势? 过去3年公司B平均发电量趋势? 分类 2021年公司B日发电量分布? 2021年各公司平均发电量分布? 多列查询 - 列出每个地区及其公司名称? 列出2022年1月1日每个公司的发电量? Where 值比较 等于、小于、大于、大于等于、 小于等于、不等于、区间、连续X 2022年1月1日发电量大于/小于/大于等于/小于等于/等于/不等于100的公司有哪些? 公司A在2022年1月1日到1月2日之间发电量的总和? 2022年1月中旬公司A连续2天的发电量总和高于100的天数? 多条件 - 公司A在2022年1月1日到1月2日之间发电量总和? 嵌套条件 - 位于北京且2000年前建成的公司或者位于上海早于2005年前建成的公司的发电量明细? 子查询 - 北京有哪个公司在2022年1月1日的发电量高于公司D在2022年的平均发电量? Groupby 成组单列 - 北京每个公司在2022年平均发电量是多少? 成组多列 - 2022年各个公司在每个地区的最大单日发电量是多少? Having 单条件筛选 - 2022年平均发电量高于100的公司有哪些?平均发电量分别是多少? 多条件筛选 - 平均发电量高于80且最大发电量大于50的地区有哪些?平均发电量分别是多少? 子查询筛选 - 2022年平均发电量高于A公司2022年平均发电量的公司有哪些? Orderby 单条件排序 - 上海各个公司中2022年1月平均发电量最高的2个公司是? 多条件排序 - 上海各个公司中2022年1月平均发电量最高的2个公司中建成时间最早的是哪个? 不支持的数据表结构:层级结构,即:每一行记录代表一个节点,节点之间存在层次关系,每个节点可以有多个子节点,如:将中国的省-市-区-县等地理数据存储在一张表中时,多为层级结构。 星型结构:将数据分为事实表和维度表(数量>3张)两部分,事实表记录了数据的度量值,维度表则记录度量值的维度信息。 不支持的问答能力:复杂的多列查询且很难使用一条查询语句获取数据的。如:参与航天日直播活动中奖的有几个人,分别是谁? 长文本类型的字段值的语义召回。如:字段值为“操作人员欠缺经验”,用户问法为:“欠缺经验导致的问题有哪些”。 需要具备特定行业或专业属性知识、特定业务知识背景的语义理解。如:财年(不同于自然年)、均值(某个总量除以数量)等。 问答测评分析基于上述问答能力边界,根据实际业务场景进行数据问答能力效果测评。 轻量测评:可直接在测试窗进行测试。相对于批量测评,测试窗测试链路更加轻便,适用于简单体验有关机器人问答效果。有关测试窗介绍可参考《全局测试窗》。 批量测评:有关批量测评操作介绍可参考《对话效果测评》。 四、问答干预问答干预主要是针对问答效果不好的点进行干预优化,主要手段包括表结构优化、增加同义词、选表干预。 表结构优化:可参考本文“业务表格数据规范”检查并优化表格使其规范化,从而模型可更好理解有关表格,进而提升问答效果。 增加同义词:通过配置表头或表值的同义词,当用户问句包含有关同义词时也可以关联到对应的表头,具体介绍可参考《数据问答干预》。 选表干预:强制机器人用指定表格知识回复有关用户问句,有关具体介绍可参考《配置机器人》召回干预部分。 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |